YOLBO - You Only Look Back Once
Introduction
Most of the progress in computer vision has centered around object detection and semantic segmentation in images. For image classification, popular networks have been ResNet, VGG Network, and GoogleNet. We have seen strong image segmentation architectures such as FCN, SegNet, UNet, and PSPNet. When it has come to video data, the most common approach has been to deploy fast object detection algorithms on each frame of the video, such as YOLO and RetinaNet. While this approach is effective, there is certainly room for improvement. By performing fast object detection frame-by-frame, all of the previous timestep information is lost, and each timestep is just a brand-new image to the object detection algorithm. The goal of this project was to investigate the incorporation of previous timestep information to increase object detection in video data. This project also provides code for performing object detection on video data.
YOLBO (You Only Look Back Once)
The approach of this algorithm is to consider the results of an object detection algorithm in previous timesteps as information to assist the algorithm’s predictions of the current timestep. Inspired by the You Only Look Once (YOLO) object detection algorithm, the YOLBO algorithm only takes information from the previous timestep into account. The core idea behind YOLBO is if RetinaNet is unsure about a detection in the current frame but was confident about a similar detection in the previous frame, then the detection is most likely valid. For every frame, RetinaNet makes a significant number of detections. Setting the threshold for what constitutes a valid detection involves a tradeoff between the total number of detections and the accuracy. Lowering the threshold may result in more valid detections, but also more invalid detections. YOLBO is able to effectively identify which of the many detections scored less than the threshold are actually valid by utilizing spatio-temporal information. To read more about this project in detail, see the associated paper.
YOLBO Algorithm
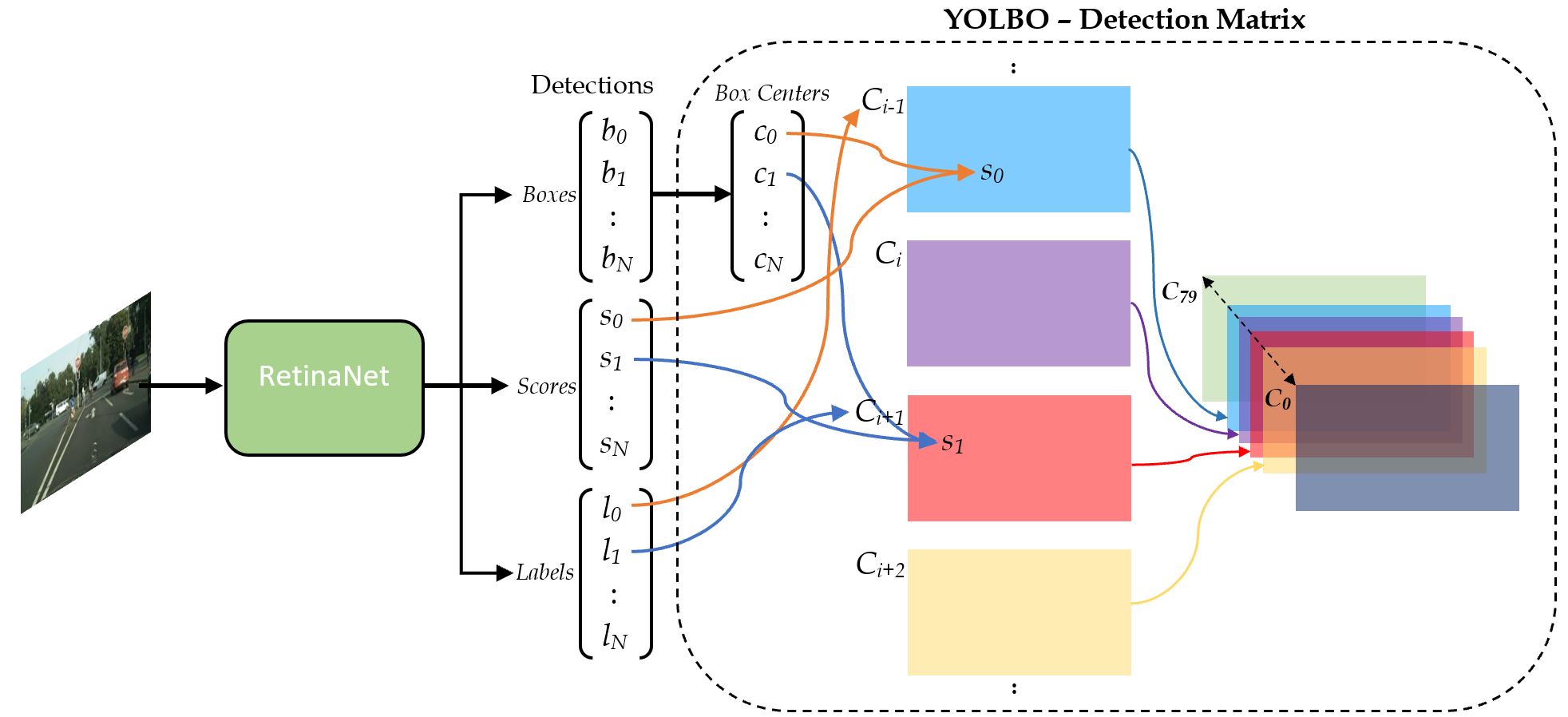
The data structure used in the YOLBO algorithm is the detection matrix, a set of spatial layers that the RetinaNet detections are mapped on to. There are N detections, consisting of bounding boxes (represented as pixel locations), scores, and labels. The centers of the bounding boxes, c, are calculated and the indices of the spatial layers correspond to the object classes {C}. The box centers and the labels are used to map the scores to a spatial layer, where l = C, at the location where the detection occurred.
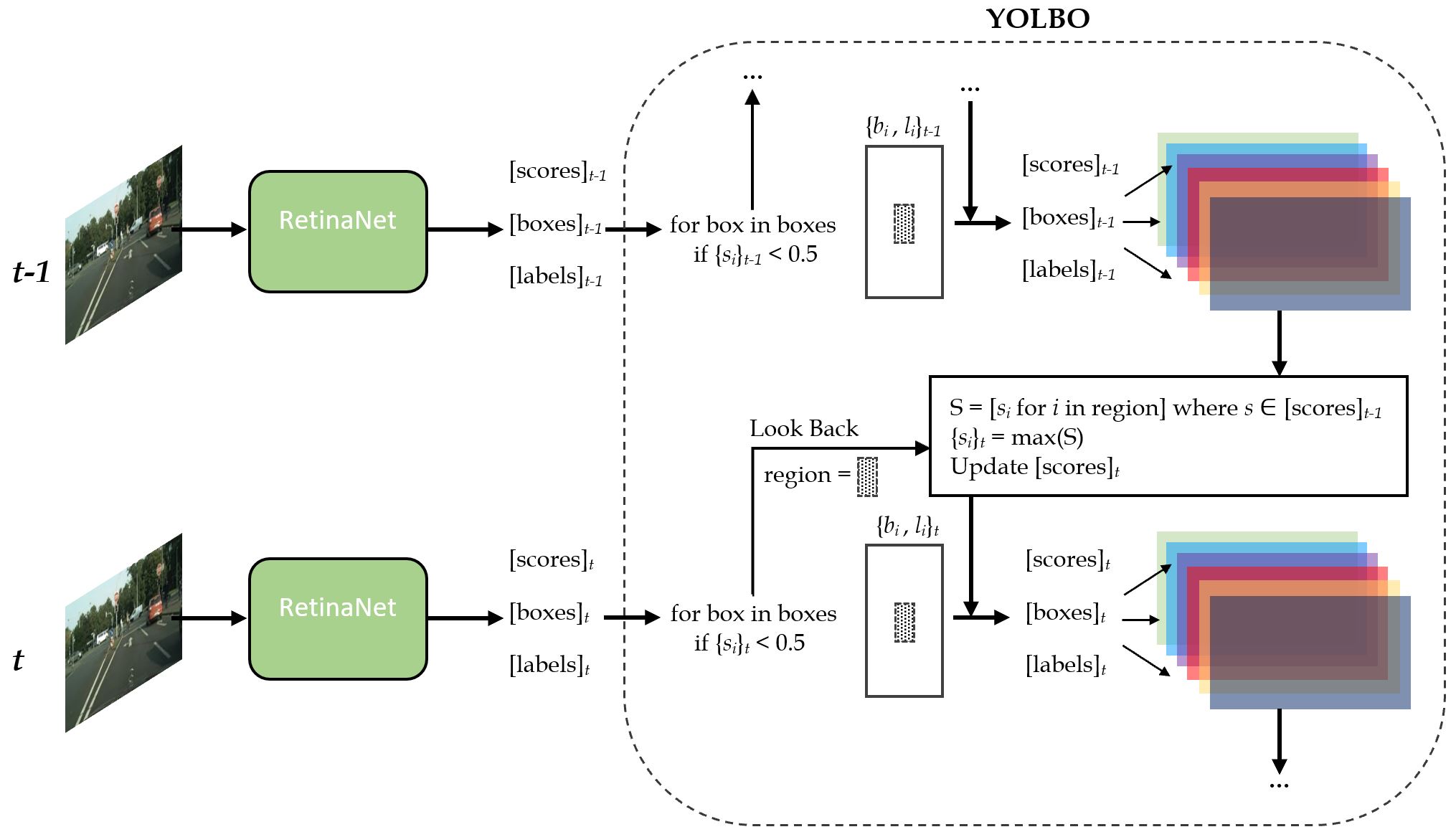
The YOLBO algorithm utilizes a Look Back function to scan for similar detections in the previous timestep. For each detection of the current frame scoring less than the 0.5 threshold, the Look Back function scans a small region around the center of the box in the previous detection matrix of the corresponding spatial layer and gathers all the scores into a list of scores, S. The max value from S will replace the detection score.
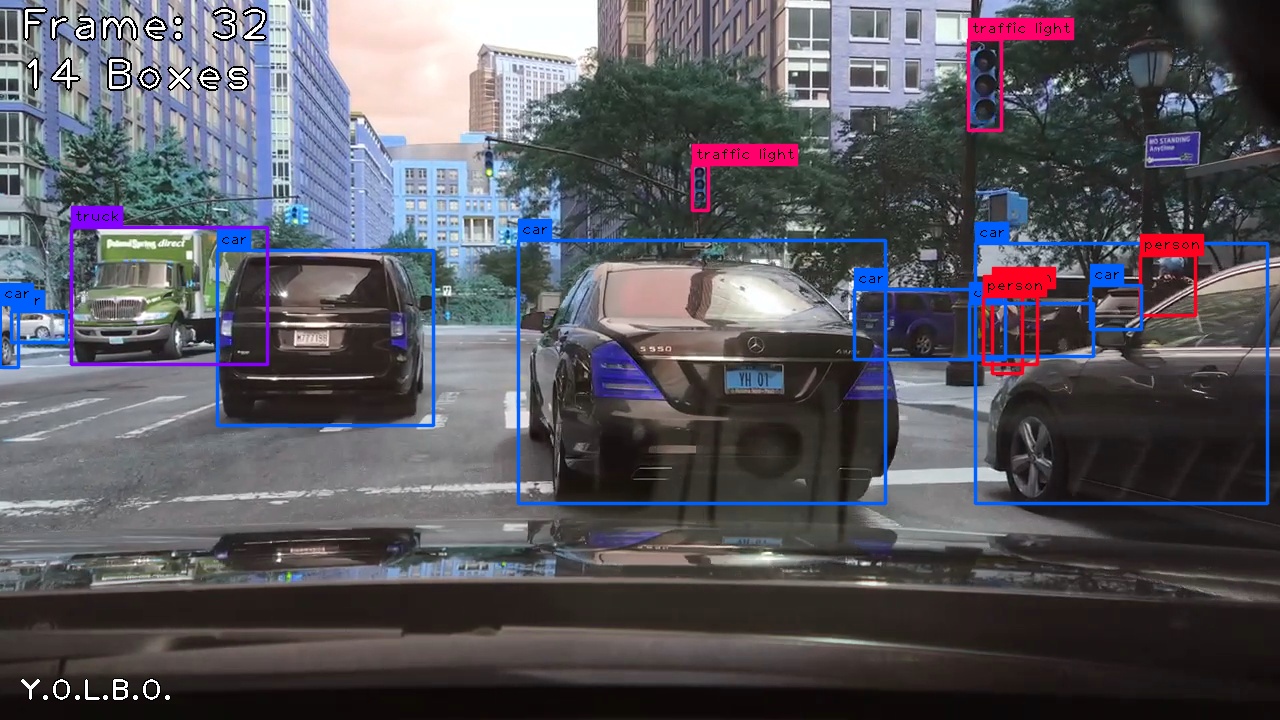
Demo
Credits
- Video data is from Berkeley DeepDrive
- RetinaNet paper: https://arxiv.org/abs/1708.02002
- Keras implementation of RetinaNet: https://github.com/fizyr/keras-retinanet